Luminescence was installed at firstsite for 3 days in April. Due to the crescendo of effort required to pull the project together followed soon after by Easter holidays and the beginning of a new term, it has take me a little while to get round to writing up my thoughts and observations.
Not long after I wrote the last post discussing my previous show Electricus, I finally got hold of a Kinect sensor. Having worked exclusively with webcam video input for the last year or more, it was a good time to cross the line into the world of the depth image and positional information. I’m particularly happy that I really ‘maxed out’ the webcam and learned so much from operating within the constraints of rgb video over an extended period before coming in from the cold. The way I see it there are two main directions to go with the (version 1) Kinect – skeleton tracking which provides fine control for a restricted number of participants or exploitation of the depth image which just gives z information in a grainy black and white low-res feed. The first approach sounds way more groovy right? But the second approach is to my mind essentially more open in the sense that it can be used to set up multi-participant interactivity with the minimum of calibration or initialisation. I really like the idea of an ‘uninvigilated’ interactive space as opposed to the invigilated version in which perhaps only 2 are allowed to approach the sensor at a time. But of course, it’s all a matter of fitness for purpose and I’m sure I’ll be maxing out the skeleton tracking functionality before long!
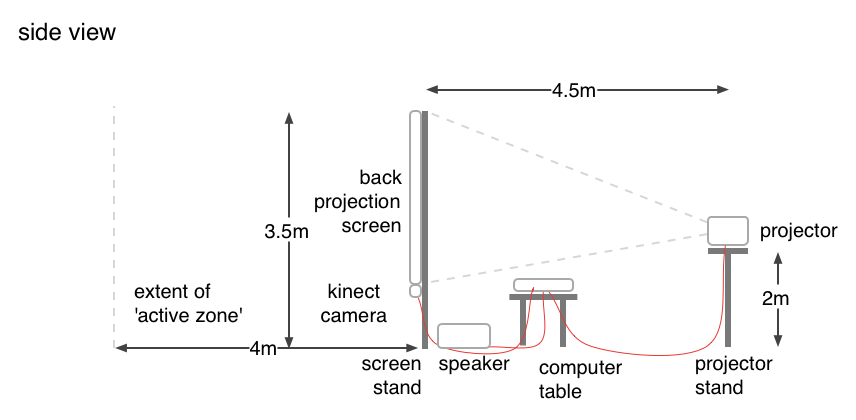
So what of the depth image? For a start, using a threshold-type filter it is simple to set up an active zone in front of the sensor thereby knocking out the background or any other unwanted objects. For Luminescence, I developed functionality that locates objects/people and draws lines around them in an approximation of their silhouette. Because the lines are drawn using a cluster of points located on the edge of a person/object’s shape, it is straight forward enough to calculate the average position of a cluster which roughly equates to the centre of a drawn shape. Once more than one shape occurs, the piece joins them together dramatically. So an individual might dwell at the edge of the active zone and experiment by putting only parts of the body (eg hands, face) into the active zone and seeing how these all connect up. A group of participants might just jump around in front of the screen and watch how the connections between their respective body shapes light the screen up.
Visitor response was very positive. I was in the installation space or close by for the duration of the event at firstsite which gave me ample opportunity to observe, chat with and generally appreciate participant interaction with the piece.